AgeNet: Deeply Learned Regressor and Classifier for Robust Apparent Age Estimation 论文笔记
摘要:这篇论文要解决的问题是表观年龄估计,即从给定人脸的图片估计该人的外表年龄,而非真实年龄(某个人可能实际50岁,但是在标注者眼中看起来像35岁),面临的最大问题是表观年龄数据样本少。
创新点
本文有两点创新:
融合了两种模型,基于实数值的回归模型以及基于高斯标签分布(Gaussian label distribution)的分类模型,两种模型都使用深度卷积神经网络来提取有表达力的年龄信息。
为了避免网络在很小的表观年龄数据集上过拟合,采用了一种从通用到特定(general-to-specific)训练方式;首先使用大规模的从互联网收集人脸图像进行分类预训练,随后使用大规模的带有噪声的真实年龄数据集进行微调,最后才在很小的表观年龄训练数据集上进行微调。
基础概念
首先需要详细定义一下表观年龄,表观年龄是在仅给出每个个体的照片的情况下由不同的志愿者标注出的年龄。与真实年龄相比,标注的表观年龄是可变的,但是不同标注者标注出的年龄均值通常是高度稳定的。本文采用的数据集是由ICCV2015 Looking at People Challenge提供的表观年龄数据集,总共包含了4699张图像,每一张图像带有一个均值标注以及标注的标准差。

然后介绍一下常见的对年龄进行编码的方式:
1-dimension real-value encoding
用一个实数值代表一个人的年龄,可以用回归模型进行建模。
0/1 encoding
把不同的年龄当做不同的类,即[0,0,0…,1,0,0],把年龄估计看做分类问题。
Label distribution encoding
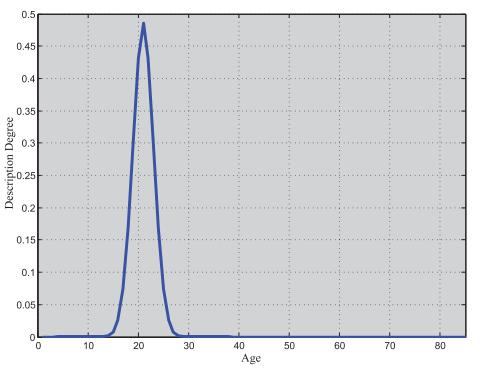
该方法的基本思想是使用每个label中的description degree来表达每一个label实例。本文具体用的是高斯标签分布,具体表述如下:对于一张给定的图片I,如果它的年龄是y,那么使用一个多维向量来表达这个年龄label,这个多维向量的第j维是:
j代表第j维(1,2,3….85),y是给出的年龄label,σ是label的标准差(因为label是由多个志愿者给出的,因此会有一个标准差),M是特征向量的最大维度(同时也是训练时可能遇到的最大年龄)。下图是一个示例:
网络总体框架
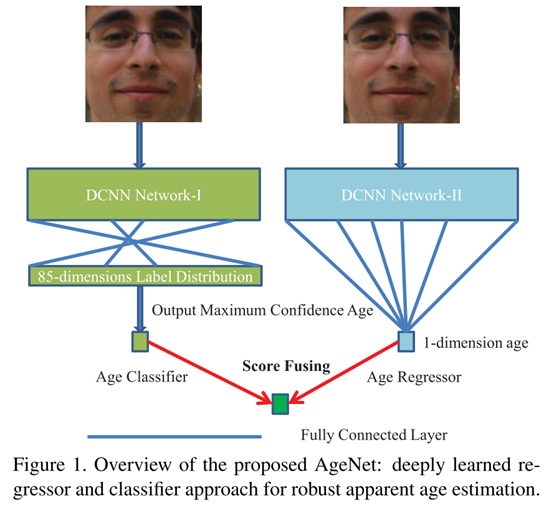
本文方法的基本思想是将年龄估计器同时建模为一个分类和回归问题,最后将两个模型进行互补性地融合来获取更好的性能。
本文的网络在GoogLeNet上进行了两处修改,首先移除了两个辅助损失层,然后在每一个ReLU前增加了BN,并且移除掉了所有的dropout来加速收敛。
在deep age regressor中,使用欧式距离来度量两个一维实值编码年龄的距离。为了避免网络中尺度不平衡的问题,在欧式距离loss前加入了sigmoid。
在deep age classifier中,年龄被编码为85维的高斯向量,使用交叉熵进行训练。
Deeply Learned Age Regressor
建模为端到端的回归问题,将表观年龄除以100,然后将网络输出的标签增加一个sigmoid层归一化到[0,1]之间。随后计算欧式loss: $$ E(W)=\frac1{2N}\sum_{i=1}^N||\hat y_n-y_n||_2^2 $$
最后的年龄估计为:
$$ R=f(\hat y_n*100+0.5) $$Deeply Learned Age Classifier
最简单的方式是使用0/1编码结合softmax loss,但是这种策略在编码距离时平等地对待了所有的年龄,没有考虑到邻近年龄估计的关系。(比如label是35岁,在网络输出35岁概率0.1、38岁的概率0.9与网络输出35岁概率0.1、80岁的概率是0.9两种情况下,产生的loss是相同的)。
因此在这里本文使用了前文介绍的label distribution方法编码,使用sigmoid交叉熵进行分类:
$$E(W)=\frac{-1} N \sum_{i=1}^N \sum_{n=1}^L[p_{in}log\hat p_{in}-(1-p_{in})log(1-\hat p_{in})]$$网络在预测时,使用输出置信度最大的那一维代表的年龄作为估计值。
从通用到特定的训练方法
即前文已经介绍的pre-train with face identities, fine-tune with real age, fine-tune with apparent age.三个阶段的训练。
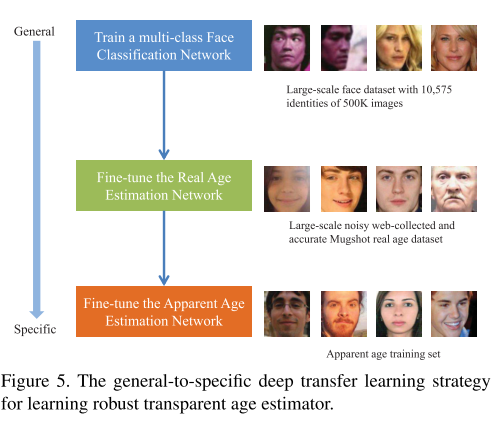
此外进行了一些人脸检测、人脸特征点定位以及人脸归一化的预处理。
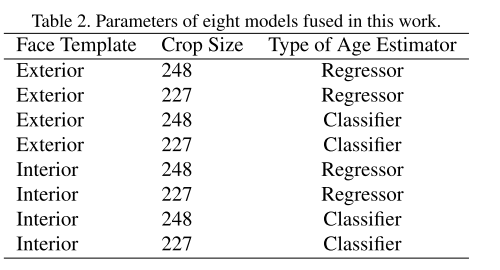
最终模型的输出融合了8个网络的结果,使用不同的裁剪大小来训练分类以及回归器,在训练阶段只使用图像中央部位的patch输入到网络。
此外,作者对比了不同迁移学习方法的性能,得出了以下一些结论:
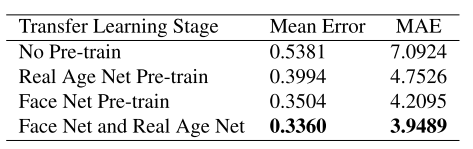
不预训练直接随机初始化训练网络时效果不好,因为网络在小的训练集上面过拟合。
预训练人脸多分类网络比在真实年龄数据集上预训练效果更好,意味着从与相似的任务上使用大规模数据集训练可以提升网络的泛化性。
尽管互联网搜集的人脸真实年龄标签有很多噪声,但是还是可以帮助提升表观年龄估计的性能,证明了这个从通用到特殊的迁移学习方法的鲁棒性。